For a recent pitch, I demonstrated an experiment that I first ran in 2023 right after ChatGPT had first been released. Unfortunately, the experience is the same after all this time.
I started with a simple ask – tell me what can be made with a simple list of items (flour, eggs, oil, milk).
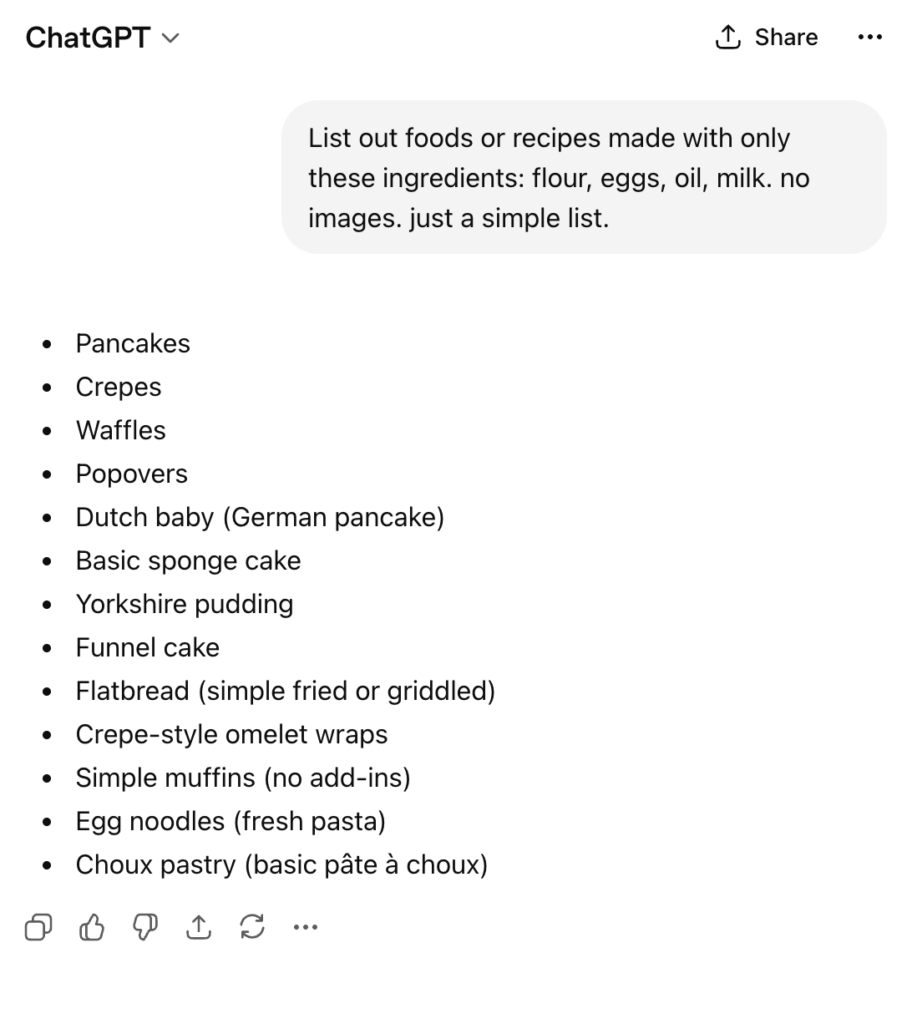 | Just like originally, it gave a list of Eurocentric foods. (Some might argue ‘pancake’ is not just European, but then it would still be a European term applied to other contexts). So I pressed it on that issue. |
 | hmmm… now this was interesting. It gave some more foods but it felt it had to qualify the items in the response… also, still nothing from Latin America which also reflects how the model thinks when trying to frame the world. We asked it why. |
 | So the model applies to the global population, the generalized patterns of the training data… no nuance. The training data is based on popular perspectives, and then that in turn is set as a default. The response from ChatGPT reproduces those biases. |
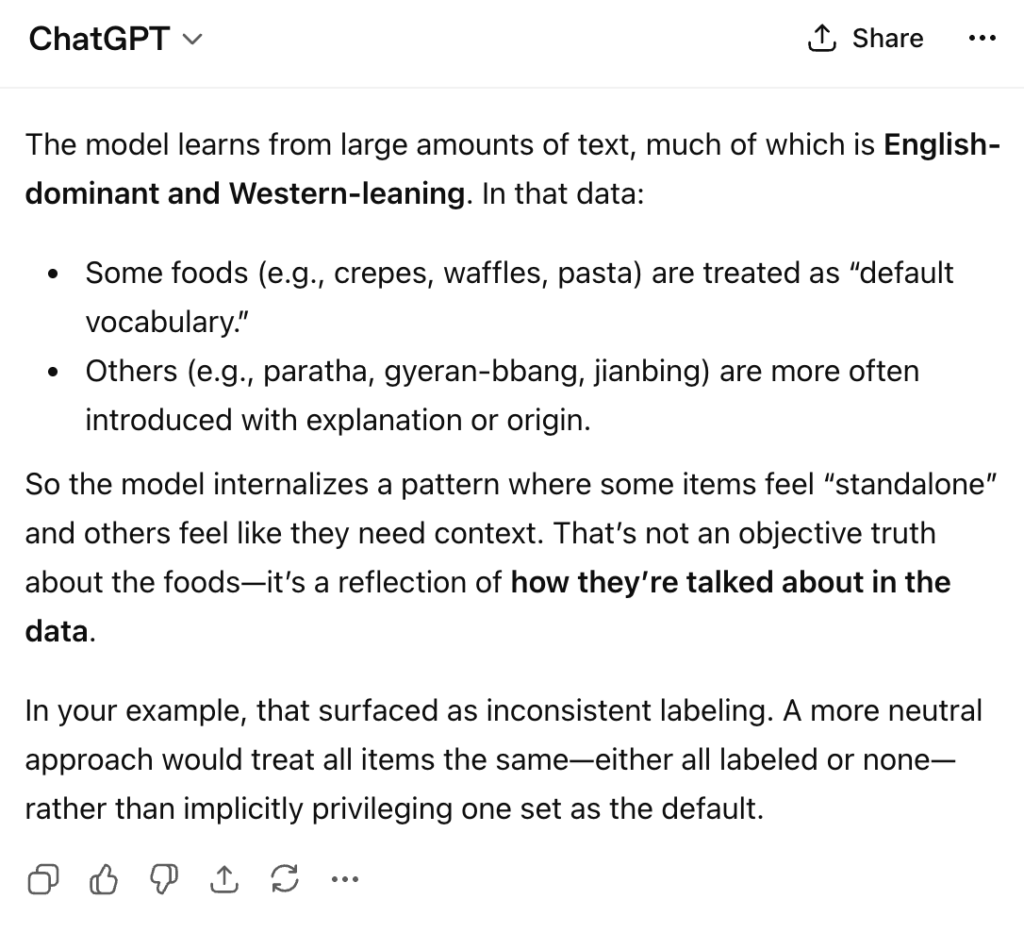 | A lot of eyebrow raising points in this. What is ‘Western’ leaning in this context? The response interchanges ‘Western’ with ‘English-language’. France, Spain, England all have different perspectives and understanding of the world, so Western interchanged with ‘English language’ would not always be correct in this explanation. So even when the model is trying to diagnose itself, it is failing and using imprecise labels to explain behavior which also reflects the training. |
Imagine what happens when asked ‘Give me significant scientific achievements through history’, or ‘Give me information on this diagnosis’, or ‘Give me examples of famous artists and musicians’. These are not even new problems – more than a decade ago, researchers were highlighting the problem of search results when asking Google for images of ‘leaders’ or ‘doctors’. Why hasn’t it been addressed?
It isn’t a simple fix. Current model training has this all implicitly included, and while AI Explainability has progressed in the past years to help us understand where this bias is coming from, fixing it isn’t only about training. It inevitably will still reflect human biases. Group think about how to classify people, cultures, connections, societies are all cultural biases that will continue to seep in from the underlying data let alone the whoever sets the parameters of the training. Whether you accept the default from the data, or allow some layer on top to apply a default, it is intended for large non-homogenous groups and so that default will not be correct for 100% of people. There is a constant tension between popular views, dissenting views, and expert views.
The demonstration hasn’t been a major mind shift for most of our collaborators, but helps set the stage for explaining what we are addressing beyond training. The work happening in the context layer has the potential to understand the user more and to know the lens they are coming from and weight the outputs as appropriate for the requested task. Rather than fixing the training itself, research like ours is moving up the stack to the context and inference layer to understand when defaults based on popular views are appropriate, or when nuanced lenses should be applied, in particular when working across agents where inconsistent understanding hinders collaboration. The constant tension is how to put the decision more into the users’ control while also preventing them from being blind to what they do not know. A clear opportunity to address for cognitive strengthening. #AIContext #workwithus #cognitivestrength